
Twin Cities PBS — Platform Discovery + 2026 Rebuild
A months-long technical discovery, architectural strategy, and full 2026 platform rebuild for Twin Cities PBS — a multi-tenant Next.js + Payload CMS application powering watch, discover, events, about, support, and tools from a single codebase, with deep PBS integrations spanning identity, video, schedule, and Passport membership.
The engagement
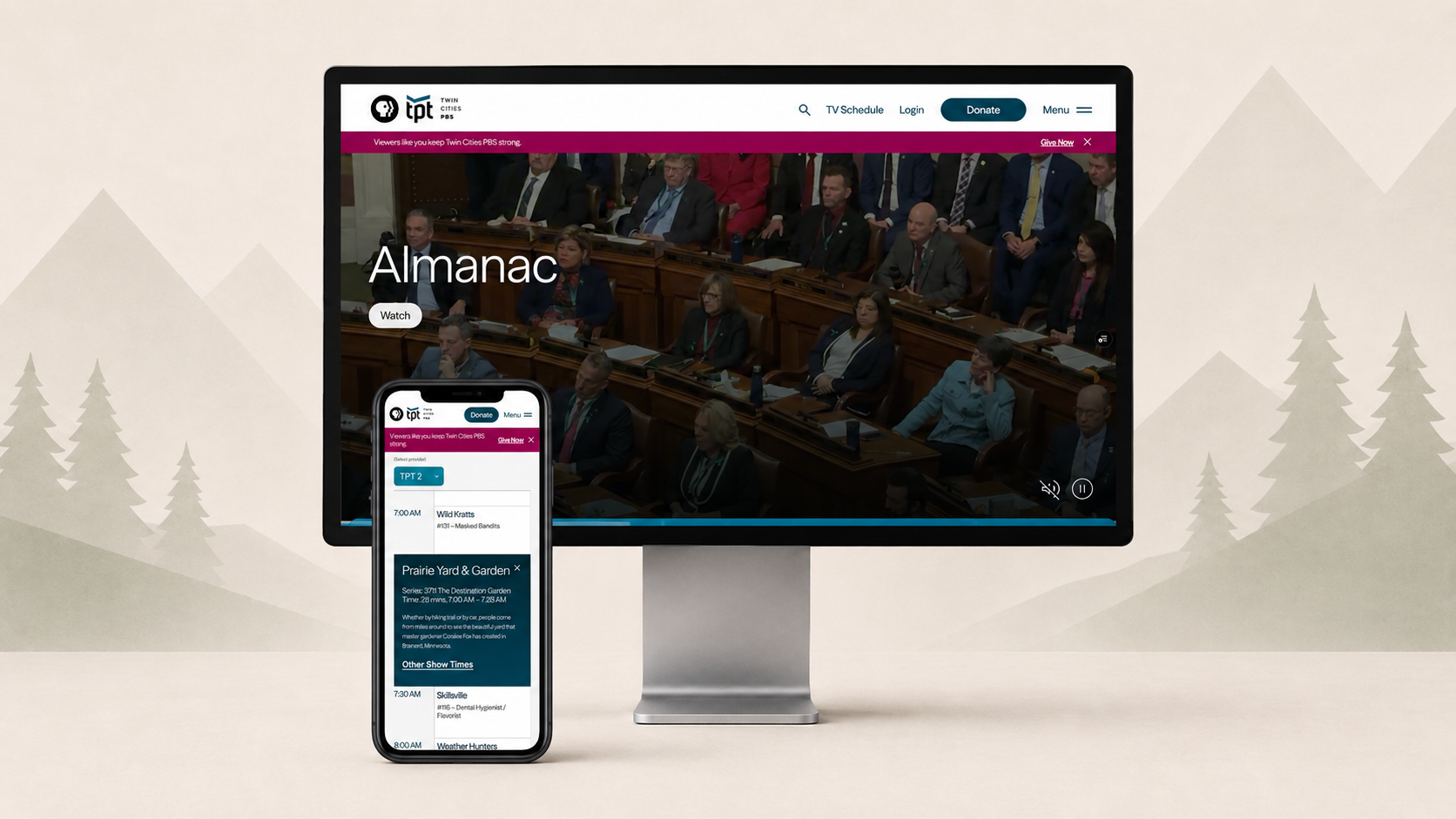
Twin Cities PBS — Minnesota's public broadcasting member station and one of the most-watched PBS stations in the country — engaged KNOCK to lead a top-to-bottom rebuild of their public digital platform. The 2026 site (tpt.org) replaces a decade-old, multi-language, multi-server architecture with a single, modern, multi-tenant application.
I led the engineering effort end to end. KNOCK's strategy, UX, and design partners shaped the editorial direction, IA, and visual system. I owned every line of code, every architectural decision, every integration.
This is the project I'm proudest of in my career so far.
Phase 1 — Discovery
Before any code was written, I led a multi-week technical discovery. The deliverable was a 60+ slide audit covering:
- Performance — real-user Core Web Vitals + Lighthouse audits across mobile and desktop, with specific opportunities surfaced for unused JavaScript, render-blocking resources, outdated polyfills, and caching policy gaps.
- Accessibility — full WCAG 2.2 review surfacing missing alt text, ARIA conflicts on focusable elements inside
aria-hiddenregions, missing skip links and focus traps, and contrast issues on the schedule page. - Security — SSL Labs and signal audits found deprecated TLS 1.0/1.1 still enabled, no CSP header, missing CAA DNS records, and no CAPTCHA / 2FA / rate-limiting on the WordPress admin login.
- System fragmentation — mapped the existing landscape of disconnected platforms (PHP, WordPress, Laravel, Flask, Rust, AWS Lambda, ECS, EC2, S3, Docker, Serverless, CircleCI, an external DXP) and surfaced where the duct tape lived.
- CMS evaluation — built a requirements matrix against ~20 criteria and evaluated WordPress, Decap, Tina, Sanity, and Payload. Payload won.
- Hosting evaluation — same matrix approach against AWS, Vercel, Heroku, Netlify. Vercel won.
- OTT path — evaluated a custom-built consume platform vs. a turnkey service (priced Muvi as the representative vendor). Documented tradeoffs for leadership to decide on.
The recommendation: rebuild on Payload + Next.js + Vercel, route legacy systems through a unified API layer, and centralize cross-system user behavior in a middleware tier.
Phase 2 — Architecture
TPT's digital ecosystem is anchored by three technology pillars I needed to integrate cleanly:
- Engaging Networks (EN) — the e-CRM. Donation forms, supporter records, email marketing, event RSVPs, the contact form, the footer signup. Exposes a REST API. We use it to create supporter records, look up donor history by email on PBS SSO login, and embed branded forms via a "2026 Site Shell" page template synced to our header/footer.
- Revolution Online (ROI) — the system of record for all customer data. Recurring donations, fulfillment, the source of truth for member history. Minimal direct engineering integration — ROI ↔ EN handle the sync between them.
- Calls Without Walls / ACD Direct — the call-center + pledge platform. Drives every pledge donation. We embed our header/footer into their forms; they handle the donation processing.
Then the PBS side:
- PBS SSO (Public Media Sign-In, Akamai Identity Cloud) — federated identity for all end users.
- PBS Media Manager — source of truth for every show, season, episode, special, and asset.
- PBS Profile Services — VPPA consent, profile metadata.
- mVault — Passport membership entitlement.
- Myers ProTrack — the on-prem broadcast scheduling system. Exports XML to S3.
Plus a custom Rust middleware called TrollyHub that runs the fast-path PBS Passport provisioning that EN's nightly sync would otherwise delay by 24 hours.
The architecture I designed:
PBS (Media Manager, SSO, mVault)
↓
Next.js + Payload CMS ←→ Engaging Networks
(single-app, multi-tenant) ↑
↓ ↓
Vercel (edge delivery) ROI CRM
Cloudflare (DNS, WAF, redirects)
↑
ACD / CWW (header/footer embed)
Myers ProTrack (XML → S3 → cron schema)Phase 3 — The build
One app, six subdomains
The most consequential decision was modeling the entire site as a single Next.js + Payload application serving six tenants from one codebase:
tpt.org/watch.tpt.org— shows, streaming, user accountsabout.tpt.org— organizational infodiscover.tpt.org— blogs, articles, editorialevents.tpt.org— event pagessupport.tpt.org— membership, fundraisingtools.tpt.org— internal utilitiespreview.tpt.org— content-preview surfaceadmin.tpt.org— Payload adminauth.tpt.org— canonical PBS SSO callback host
Tenant resolution is host-based, not path-based. getSubdomainFromHost() reads the Host header at request time, defaults to watch for the apex, strips environment markers (<tenant>.local.tpt.org, <tenant>.preview.tpt.org), and pulls per-tenant config out of a single SiteSettings global by namespaced field prefix (watch_title, discover_favicon). One Payload doc, N tenants. No duplicate deployments, no copy-pasted code, no drift.
PBS SSO — hand-rolled OAuth 2.0 + OIDC + PKCE
I built the PBS auth layer from scratch rather than reaching for NextAuth, because the requirements were too specific: PBS uses Public Media Sign-In (Akamai Identity Cloud) as the IdP, requires VPPA consent gating, requires PBS Profile Services lookups for pid resolution, and requires mVault lookups for Passport entitlement — all of which need to be folded into a single session before any UI can render.
The implementation:
// /api/pbs-auth/login → /api/pbs-auth/callback (6-step exchange)
// 1. Token exchange (authorization code + PKCE verifier)
// 2. /userinfo → email, name, sub
// 3. PBS Profile Service → pid, vppa_accepted
// 4. mVault → passportActive, ppuid
// 5. Mint signed JWT cookie (jose / HS256, 14d, .tpt.org domain)
// 6. Redirect back to originating tenant via state.returnToA single signed JWT cookie (tpt_auth) scoped to .tpt.org makes the session shared across every subdomain. The accessToken lives inside the cookie but is never exposed to the browser (httpOnly); server routes read it back to mutate PBS-side state (e.g. PATCH /v2/user/profile/ for VPPA acceptance). No user data lives in our Postgres — every session check is a cookie verify + decode.
The canonical callback host (auth.tpt.org) is the only URL PBS whitelists. Login from any tenant flows through it and uses state.returnTo to bounce back. Without that indirection, every tenant would need its own PBS allowlist entry.
PBS Media Manager ingestion — cascading sync
PBS Media Manager is the source of truth for every show, season, episode, special, and asset. I built a parent-first cascading ingestion pipeline that walks the PBS API and upserts into Payload collections:
Shows → Seasons → Episodes / Specials → AssetsEach layer is a standalone handler that paginates the PBS API, normalizes records, and upserts via mm_id (Media Manager ID) as the dedupe key. Progress is journaled to disk so a ctrl-C mid-run is recoverable. The shared upsertDocument() primitive looks up existing docs by mm_id → id → slug and either updates in place or creates. The full cascade runs about 4–5 days end to end against the live PBS API and is rate-limit-aware.
Assets carry their full lineage denormalized (show, season, episode, special IDs all stored on the asset record) so the front-end can render show pages without traversing relationships on every query.
A cron route at /api/cron/pbs-changelog runs every minute against the PBS Changelog endpoint to catch incremental updates without re-walking the full hierarchy. The changelog has a 30-day window — if sync goes sideways, there's a recoverable restore point.
Myers ProTrack — XML schedule sync via two process models
The on-air broadcast schedule lives in Myers ProTrack, which exports XML to an S3 bucket. The pipeline runs in two completely different runtime models because Vercel's serverless functions can't host long-running processes:
- Standalone Node cron server (
server.ts) — a long-running container that boots a minimal Payload instance scoped to a dedicated Postgrescronschema, listens for SIGINT/SIGTERM, and runs the sync nightly at 4 AM vianode-cron. - Vercel cron HTTP endpoint (
/api/cron/sync-xml) — stateless, secret-gated, called by Vercel's cron service on schedule. SamesyncXmlFromS3function, different invocation.
Both write to a separate cron schema in Postgres (not the editorial public schema) to isolate the high-write churn from CMS reads. The sync uses SHA1 content hashing to skip unchanged episodes — syncHash = sha1(stableStringify(episodeData)) — meaning a typical nightly run touches only the deltas, not all 5,000+ episodes per channel.
The read path (/api/cron/schedule) bypasses Payload entirely and runs raw SQL with a 4-step CTE chain to snap times to a 30-minute grid, dedupe overlapping rows, and convert UTC → America/Chicago for the local-day query:
WITH raw_rows AS (...),
central_day AS (... AT TIME ZONE 'America/Chicago' ...),
snapped AS (... 30-minute slot rounding with 15s tolerance ...),
ranked AS (... 4-tier dedupe ORDER BY ...)
SELECT * FROM rankedPledge Drive automation
Pledge drives are mission-critical for public media. During drives, donation URLs (/give, /sustaining, /all-creatures-great-small-passport, etc.) need to redirect to a specific pledge-mode destination; outside drives, they go to the standard donation page. I built a Cloudflare-driven redirect controller managed from Payload:
- Pledge Drive Windows — specific date/time ranges (multi-day fundraising drives).
- Weekly Override — a recurring weekly schedule (e.g. ON Friday 6PM, OFF Sunday 11PM) for routine pledge nights.
- Default — falls through to the standard donation URL.
A cron job checks every 8 minutes, evaluates the priority chain (windows > weekly > default), and if the target needs to change, calls the Cloudflare API to update the redirect rule and emails a notification with the previous/new URL and timestamp. The Membership Team manages all of this from Payload without ever touching Cloudflare.
AI vector embeddings for future chatbot
Every show, season, episode, special, and asset gets serialized into a single "Search Index" document on update, then converted into a vector embedding via OpenAI's text-embedding-3-small model. The embeddings are stored in Postgres via pgvector with the same Postgres adapter Payload uses. The immediate value is improved site search. The longer-term plan is a TPT chatbot that can answer "when does Antiques Roadshow air this week?" using RAG against the embeddings.
Live preview that actually works
Payload's Live Preview surface renders into an iframe scoped to preview.tpt.org. The URL resolver does two clever things: (1) it unwraps "review" documents — if the doc has a relatedDoc.value/relationTo reference, it fetches the actual underlying doc so the preview targets the real content rather than the review record; and (2) it routes by content type — detecting events, resources, posts, blogs, and topics from doc shape and rewriting the preview URL to the correct tenant + collection. Both the production renderer (PageRouter.server.tsx) and the preview renderer (PageRouterClient.tsx) delegate to the same RenderBlocks switch, so any block renders identically in both surfaces.
Local dev that mirrors production
To make the multi-tenant + HTTPS-only + cookie-domain architecture work locally, I set up:
- dnsmasq to resolve
*.local.tpt.org→127.0.0.1 - Caddy as a reverse proxy terminating HTTPS using mkcert-generated certs
- Docker Compose for Redis (and a currently-unused Mongo)
/etc/hostspinning forauth-dev.tpt.org,admin.local.tpt.org,preview.local.tpt.orgbecause those need to be deterministic
A fresh engineer can clone, install, and have the full multi-tenant local environment running in under an hour.
Block-based content authoring
The whole front end is composed from a library of reusable, brand-locked layout blocks that editors compose via Payload:
- Show Hero (with background video / image, multi-slide carousels, show-relationship binding)
- Watch Live (with
?channel=deep-linking and anchor-scroll) - Text + Image, Impact Statement, Media Full-Bleed, Stats, Testimonials
- Card Grid, Card Carousel, Info Tile Carousel, Logo Grid
- Action with Image Ribbon, Post Feed, Featured Posts, Video/Watch components
- Forms and embeds, FAQ accordions, Pledge Drive CTAs
Each block has locked field types so editors can't break the design system — they pick from defined backgrounds (color / image / gradient / video), themes (light / dark), spacing presets, and typography that's already on-brand. The Lexical editor handles rich text. There's even a debug hotkey (Ctrl+Option+Q) that shows block-type labels on the front-end for editorial review.
Identity, redirects, and operational realities
A few of the smaller battles worth flagging:
- Cookie domain pinning — the session cookie is scoped to
.tpt.orgso it's shared across all six tenants.secure: trueis hardcoded, which means local dev requires HTTPS, which means Caddy isn't optional. - Split-DNS redirect drift — TPT's internal network bypasses Cloudflare and resolves directly to Vercel. Cloudflare-only redirects (
/give,/givenow, etc.) were silently 404'ing for internal users. I duplicated the critical rules intovercel.jsonand documented the long-term fix (route internal traffic through Cloudflare). - PBS's canonical-host indirection — every login from any tenant has to round-trip through
auth.tpt.org/api/pbs-auth/callbackbecause PBS only whitelists that one URL. Thestate.returnToparameter is the only thing connecting the originating tenant to the post-login destination. - The TrollyHub Rust service — left in place because rewriting it was out of scope, but flagged in the discovery as a future consolidation target.
- No user table — PBS users never land in our Postgres. The Payload
Userscollection is for CMS staff only (via OAuth2 with email allowlists by role: admin, blogger, resourcer, member).
What I delivered
- The full technical discovery deck (60+ slides, presented to TPT leadership)
- The future-state architecture diagrams (with and without OTT)
- The complete production application: Next.js 14 App Router + Payload CMS + Postgres + Supabase S3, deployed on Vercel
- Multi-tenant infrastructure serving six subdomains from one codebase
- The PBS SSO integration (custom OAuth 2.0 + PKCE + cookie-based sessions across all tenants)
- The Media Manager cascading ingestion pipeline (Shows → Seasons → Episodes/Specials → Assets)
- The Myers ProTrack XML schedule sync (two runtime models, hash-based diff, raw-SQL read API)
- The Pledge Drive redirect automation (Cloudflare API integration, Payload-driven scheduling)
- The AI vector-embedding pipeline (OpenAI + pgvector) for future chatbot
- Live Preview, audit logs, publication workflows, role-based access control
- Full engineering documentation — onboarding, multi-tenancy, auth, ingestion, schedule sync, redirects, dev environment setup
Why I'm proud of this one
Public media stations don't get to fail gracefully. They rely on this kind of platform to drive membership, to deliver the on-air schedule grid to a live audience, to gate VPPA-protected video, to run pledge drives that fund the next season of programming.
Getting this right required more than picking a stack. It required understanding PBS's identity flows well enough to integrate them from scratch. It required understanding the call-center / e-CRM / CRM triangle well enough to know where the integration boundaries were. It required understanding Payload deeply enough to know which features to lean on (Live Preview, audit logs, workflow plugins, the S3 adapter, the OAuth2 plugin) and which to build around. It required understanding Next.js App Router and Vercel's edge model well enough to build a multi-tenant single-app architecture that doesn't fall apart at scale.
I built every piece of it. I'm proud of the work.
If you're considering a similar engagement — public media, nonprofit, or enterprise — let's talk. Reach out.